

Namely recently launched our Benchmarking Package to clients, an offering which provides quarterly reports of company-specific insights with tailored benchmark data layered directly on top. Never before has it been so easy for mid-sized companies to understand the health of their talent compared to other companies just like them.
As part of the offering, we leveraged data science and machine learning to make it easier than ever before to compare the specific reasons employees are leaving one company relative to its peers. In light of this exciting news, I thought it would be fun to introduce all of my fellow data nerds out there to the process behind developing, testing, and launching Namely’s benchmarks.
What’s Behind a Namely Benchmark?
When we started this benchmarking work in 2018, we knew that Namely was in a unique position to explore and provide aggregated insights back to our clients and the broader HR community. While most providers of HR benchmarks collect their data through surveys sent to a variety of organizations, Namely’s historical data is a direct link to the realities of thousands of mid-sized organizations and hundreds of thousands of employees, no intermediary necessary. As a result, our benchmarks are not subject to biases resulting from incomplete benchmark survey responses or poor response rates. In other words, we can provide a more comprehensive view of the workforce at any point in time without repeating large scale surveys. This means we can produce a greater variety of benchmarks with greater speed—and continually adapt to meet the needs of the benchmarking clients we work with.
Finally, in an effort to provide never-before-seen benchmarks on the exact reasons employees leave their companies (there are thousands of ways companies label employees terminations), we’ve leveraged data science and machine learning to cluster and classify thousands of departure reasons into a standard set of 32 reasons that can be benchmarked across all companies. All of this preparation led to the launch of the Namely Benchmarking Package and a new era of Namely providing HR insights. Once we decided to research and generate HCM benchmarks, we knew there would be several key decision points along the way that ensure our benchmarks are of a high-quality and great relevance to HR professionals. Three decision points I’ll share with you today include:
-
How do we determine the minimum number of companies that would form a valid benchmark?
-
How do we determine the minimum number of employees that would form a valid benchmark?
-
Should we report the mean or the median of a number (e.g., employee turnover)?
1) Minimum Number of Companies
As part of our research and development process, we reached out to our partner Culture Amp to discuss their process for developing engagement benchmarks. They had used a statistical process called bootstrapping (repeatedly calculating the same metric, like turnover rate, based on a random sampling of different numbers of companies to observe how spread out the metric in each of these ‘samples’ is) to determine that their engagement benchmarks stabilized once about 20 companies were included. We adopted a similar approach to developing our benchmark and found that our results mirrored theirs! Specifically, our turnover benchmarks stabilized when we sampled a minimum of 20 companies.
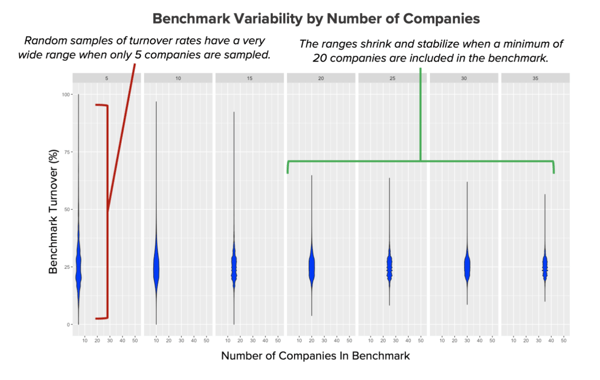
2) Minimum Number of Employees
Having determined the appropriate minimum number of companies, we turned next to a number of employees. In fact, we took a very similar approach to identify the optimal employee minimum in Namely benchmarks. Here’s a slightly different visual showing that benchmark numbers stabilize dramatically during the first 5,000 employees, and continue very gradually until 10,000 employees, after which the progress is negligible.



Get the latest news from Namely about HR, Payroll, and Benefits.


Get the latest news from Namely about HR, Payroll, and Benefits.
